Switch Transformers: Scaling to trillion parameter models with simple and efficient sparcity (2021)
1. Introduction
- 큰 언어 모델의 성공에 영향받아 sparsely-activated expert model: Switch Transformer가 탄생
- 희소성은 샘플 데이터로부터 뉴럴 네트워크 가중치 일부(subset)을 활성화하는 방식으로 제안한다
- 효율적인 sparse algorithm은 Mixture-of-Experts(MoE) 패러다임에서부터 시작한다
- Switch Transformer는 슈퍼컴퓨터 뿐만 아니라 적은 수의 코어를 가진 컴퓨터에서도 좋다
- T5 모델을 pretraining할 때 (7+α) × 의 속도가 향상되었다.
- sparse pre-trained & specialized fine-tuned 모델을 작은 dense model로 성공적으로 증류하였다.
- large sparse teacher의 성능 향상 30%를 유지하면서 모델 크기를 99% 감소시켰다.

- Transformer에서 Fully-Connected FFN layer를 Switch FFN Layer로 치환하였다.
- 각 토큰은 독립적으로 각 층에서 처리되며, 그림의 경우 4개의 FFN experts가 존재한다
- Router는 각 토큰을 독립적으로 하나의 expert로 보내고, FFN은 router gate value를 곱하여 값을 반환한다
2. Switch Transformer
- 큰 언어 모델의 성공에 영향받아 sparsely-activated expert model: Switch Transformer가 탄생
- 우리의 훈련 환경에선 sparsely activated layers는 각 장치에 고유한 가중치를 나눠서 활성화한다
- Shazeer (2017)은 자연어의 MoE 층을 제안, input token이 top-k experts에 의해 결정되어 route된다
- route될 때 확률은 softmax함수에 따른다
- 우리의 모델은 단 하나의 expert에 라우트하는 단순한 방법으로 모델 성능을 유지하면서 연산량을 줄였다.
- 각 토큰은 가장 높은 확률값을 가진 expert로 라우트된다
- 그로 인해 1) 연산량 감소 2) 배치 사이즈 증가 3) 라우팅 구현 단순화, 데이터 전송 cost 감소
- expert capacity = (tokens per batch / number of experts) × capacity factor
- expert capacity는 각각의 전문가가 계산하는 토큰 수
- capacity factor > 1.0일 때 토큰이 각 expert에게 라우트되어 수용되기 위한 추가 버퍼가 생성됨
- expert capacity가 증가하면 연산량과 메모리 비효율이 발생하는 trade-off가 존재한다
- 각 experts에 균등한 부하분산을 하기 위해서 추가적인 loss (auxiliary loss)를 각 Switch layer에 추가한다
- 자세한 내용, 식은 식 (4) 참조
- 각 층에서 실행되는 hard-switching(routing) 때문에 결과의 불안정성이 생길 수 있다.
- fp16을 사용할 경우 router의 softmax 연산 시 상황을 더욱 악화시킬 수 있다.
- 우리는 selective-precision을 사용함으로써 비슷한 결과를 더욱 빠르게 훈련시켜 얻을 수 있었다.
- 가중치 초기화도 중요한데, mean = 0, var = (s/n)^0.5, s : scale hyper-parameter
- s가 작을수록 model quality가 더 좋고 안정적으로 훈련된다
- Swich Transformers는 parameter 개수가 많기 때문에 downstream task에서 오버피팅되기 쉽다
- 따라서 fine-tuning 시에 drop-out rate를 상당히 높여 이 문제를 해결할 수 있다
- expert layer에서는 0.4, non-expert layer에서 0.1로 설정했을 때 가장 좋은 결과가 나옴
3. Scaling Properties
- experts의 수를 늘려도 computational cost는 거의 고정되는 경향이 있다. O(d_model × N_experts)
- T5-Base 모델에서 N_experts = 64일 때 7배 빠른 훈련 시간에 비슷한 성능(log-perplexity)을 보임

5. Designing Models with Data, Model, And Expert-Parallelism
- Expert, Model, Data Parallelism을 모두 사용하면 통신 비용을 줄일 수 있다.
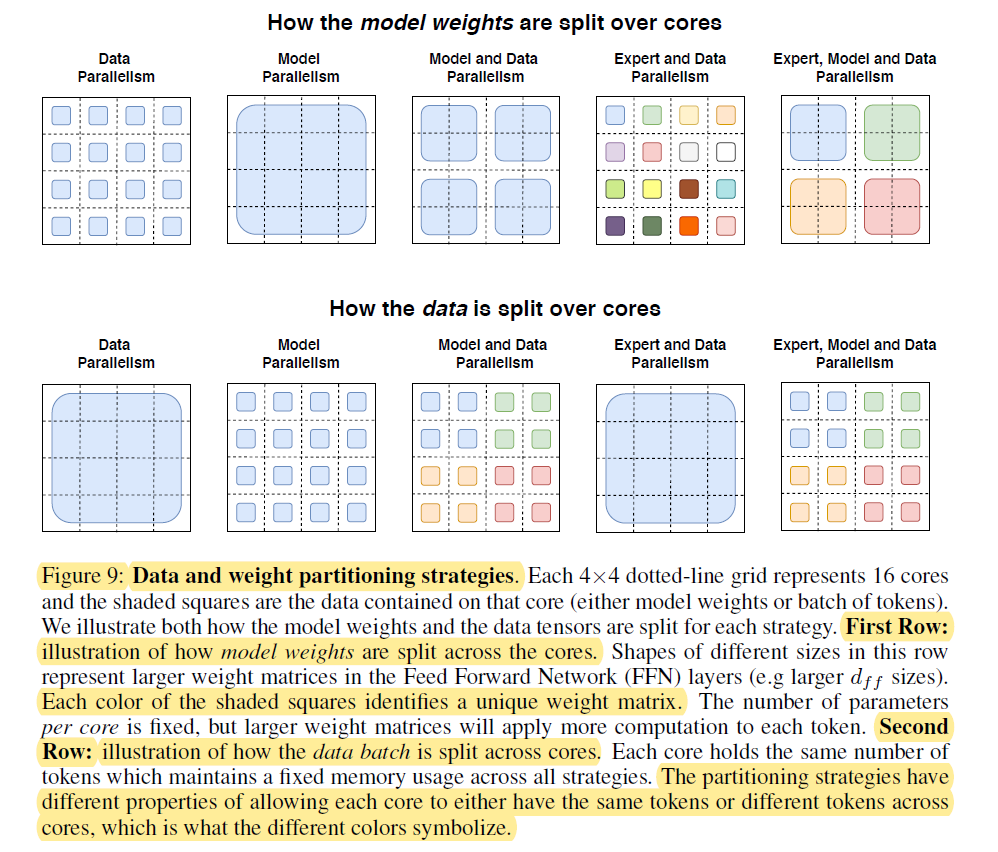
후략..
'AI - NLP > Articles' 카테고리의 다른 글
| Deep Learning Based Recommendation: A Survey (2017) (0) | 2021.02.22 |
|---|---|
| Overview of the TREC 2020 Deep Leaning Track (2021) (0) | 2021.02.17 |
| Scaling Laws for Neural Language Models (2020) (0) | 2021.02.05 |
| 딥러닝 모델 병렬 처리 (2018) (0) | 2021.02.05 |
| Transformer Feed-Forward Layers Are Key-Value Memories (2020) (0) | 2021.02.05 |
